Pandas 101 Part-1

บทความนี้ถูกเขียนด้วยแนวคิดที่ว่า ทำอย่างไร จึงสามารถใช้ Pandas ได้อย่างครอบคลุม โดยที่มีใช้ความรู้น้อยที่สุด เพราะฉะนั้น ผู้เขียนจึงคัดมาแต่คำสั่งที่ผู้เขียนบทความคิดว่า ผู้เขียนได้ใช้บ่อย เท่านั้น
ต้องอธิบายเพิ่มด้วยว่า ผู้เขียนสนใจ data science เป็นงานอดิเรกสนุกๆ ถ้ามีเรื่องอะไรอยาก discuss ถ้ามีคำแนะนำ,ติชม จะเป็นเรื่องที่ผู้แต่งยินดีมาก
เพื่อความเข้าใจทีดียิงขึ้น เจ้าของบทความเลือกที่จะเทียบเคียงกลุ่มของ Function ให้ใกล้กับ Functional Programming (แค่เทียบเคียง บางกลุ่มอาจจะไม่ตรงกันเป้ะๆ) กระนั้นผู้อ่านสามารถอ่านบทความนี้ให้เข้าใจได้โดยที่ไม่ต้องทราบแม้แต่ Concept ของ Functional Programming เลย
ถ้าเพื่อนๆสับสน จะด้วยเนื้อหาหรือภาษาของผู้เขียนก็ตาม ขอให้คิดว่าโดนเจ้าของบทความหลอก เมื่อเพื่อนๆอ่านจนจบ จะเห็นว่า ทุกจิ๊กซอร์ทีกระจัดกระจาย จะรวมเป็นภาพใหญ่แผ่นเดียวได้เลย แล้วถ้าอ่านจนจบแล้วไม่เห็นภาพใหญ่ที่ประกอบมาแล้วหล่ะก็…. ยินดีด้วย เพื่อนๆได้ความรู้สึกของการดู To Aru Series โดยที่ไม่ต้องดูแล้ว
คำเตือน บทความนี้ เพื่อนๆควรจะมีความรู้เกี่ยวกับ Pandas ในระดับนึงก่อน อาจจะเป็นเคยจับ Example ง่ายๆ หรือลองใช้เล่นๆซัก 1 ชม.ก็น่าจะเพียงพอต่อการอ่านบทความแล้ว
1. Map Function
Function ที่รับ Data Frame (N x M)หรือ Series (N) เข้าไป แล้วรีเทิร์นเป็น Data Frame (N x M )หรือ Series (N) ที่มีขนาดเท่าเดิม
1.1 Operator ( +,-,*, / , ==,!= <,> ,&& ,|| ,etc.)
เราสามารถ +,-,*,/ ใส่ Data Frame(Series) ตรงๆได้เลย อย่างเช่น
df[‘SalePriceWithTax’] = df[‘SalePrice’] * 1.07
เพิ่มเติม การที่เรานำบวก,ลบ หรืออะไรก็แล้วแต่ที่เป็นตัวดำเนินการทางคณิตศาสตร์ ไปใช้กับ data type ที่ไม่ใช่ data type พื้นฐาน ( Primitive data type) ได้ เรียกว่า “overload operator” (คืน อ.กันไปหมดแล้วหล่ะสิ )
นอกจากจะใช้ระหว่าง series กับ numeric ได้แล้ว เรายังสามารถ ใช้กับ series และ series ทีมีขนาดเท่ากันได้อีกด้วย
df[‘PriceAreaRatio’] = df[‘SalePrice’] / df[‘LotArea’]
1.2 .isnull()
ในแต่ละช่องของ Data Frame (หรือ Series) ถ้ามีค่าเป็น Null จะคืนค่า True ถ้าไม่ใช่จะคืนค่าเป็น False
แน่นอนว่า การได้ Data Frame ที่เพียงแค่บอกว่า ค่าไหนเป็น Null คงไม่สามารถช่วยอะไรเราได้ เพราะเราจะไม่ไปนั่งนับใน Data Frame แน่นอน จึงต้องใช้คอมโบกับฟังค์ชั่นในหัวข้อถัดไป
df = df.isnull()
1.3 .apply()
แล้วถ้าเราไม่อยากใช้แค่ บวก,ลบ ล่ะ เราจะใช้ x in y (หาตำแหน่งของ substring) , เราจะใช้ .substring() (string -> substring) หรือ Method ที่เราสร้างขึ้นเอง จะทำยังไง
แน่นอนว่า pandas ไม่สามารถ “overload operator” ทุก operator บนโลกได้
ความเป็นจริง เราสามารถ for ตรงๆเพื่อเอา Method ข้างต้นไปทำกับทุก row ใน Data Frame ได้ แต่ในยุคของ Functional Programming เรายังจะวน for กันอยู่อีกหรอ แถมยังเสียความเป็น Pure Function อีกตังหาก (ถ้าลองสังเกตดู ทุกฟังค์ชั่นใน pandas เป็น Pure Function หมดนะ)
.apply() จึงเกิดมาเพื่อแก้ปัญหานี้ โดยตัว .apply() เองจะรับ Function 1 ตัว แล้วนำ Function นั้นไปทำกับทุกแถวและคอลัม ใน Data Frame เลย (ใครที่เขียน JS จะเข้าใจว่า นี่มัน .map() แน่นอน)
ตัวมันเองต้องมาคู่กับ lambda function ตาม รูปแบบด้านล่าง
df.apply( lambda x: f(x) )
def ftax(x):
if(x<100000):
return x
elif (x<200000):
return x*1.1
else:
return x*1.2
df['SalePriceWithTax'] = df['SalePrice'].apply(lambda x:ftax(x))
โดยปกติแล้ว Method ที่นำมา Map มันถูกใช้เพียงครั้งเดียว จึงนิยมเขียนแบบ “Anonymous Method” ดังตัวอย่างข้างล่าง
df['SalePriceWithTax'] = df['SalePrice'].apply(
lambda x: x if x < 100000 else
x*1.1 if x< 200000 else
x*1.2 )ตัวอย่างข้างบน ใช้วิธี Short Hand If Statement เข้าช่วย
def abs(x):
if x>0 :
return x
else:
return -x //Normaldef abs(x):
return x if x>0 else -x//Short Hand
2.Reduce Function
Function ที่รับ Data Frame (N x M )เข้าไป แล้วคืนค่าเป็น Data Frame (N x 1)หรือ รับ Series (N)เข้าไป แล้วคืนค่าเป็น Value (1)
.sum() , .mean() , .max() , .quantile() , .unique() ,etc.
ที่ต้องรู้ก็คือ ถ้า Reduce Function ถ้าโยนใส่ Data Frame จะกระทำกับ ทุก Column ใน Data Frame แต่ในความเป็นจริง .sum() , etc. มันใช้กับตัวเลข ยังไง Data Frame ก็น่าจะมี string ปนๆมาบ้างอยู่แล้ว ปกติเลยมักใช้กับ Series เท่านั้น
อย่างไรก็ดี เราจะเห็นประโยชน์ของกลุ่มนี้ชัดๆใน Part 2
3.Filter Function
เจ้าของบทความใช้รูปแบบเดียวคือ
3.1 df[series]
โดย series นี้จะต้องเป็น series ที่มีแถวเท่ากับแถวของ Data Frame และ มีค่าเป็น True,False (อาจจะ 0–1 ก็ได้) แล้วเราจะหา series แบบนี้มาจากไหนหล่ะ ? คุ้นๆใช่ไหม
แน่นอนว่าต้องหยิบมาจากกลุ่ม Map Function ที่กระทำกับ series
แล้วถ้าต้องการใช้สองเงื่อนไขหล่ะ? อย่าลืมว่า && , || เป็น Operator ตัวนึง ซึ่งสามารถใช้ระหว่าง series และ series ได้ (อย่างทีเกริ่นไว้ใน Operator ) เพราะฉะนั้น เราสามารถเขียนแบบนี้ได้
แทนที่จะใช้ df[series] เรายังสามารถใช้ df.loc[series] ได้ด้วยนะ
4.Sorting
การจัดการข้อมูลจะขาดการเรียงอันดับไปไม่ได้เลย ใน pandas จะใช้ syntax ตามนี้
df.sort_values(by = c, ascending = b)โดย c เป็นชื่อคอลัมน์ที่ต้องการเรียง ตรงนี้หลายคนอาจจะไม่ทราบว่า นอกจาก c เป็นชื่อคอลัมน์ได้แล้ว ยังเป็นลิสต์คอลัมน์ได้ด้วย , b เป็น Boolean ที่จะบอกว่า ข้อมูลเรียงจากน้อยไปมาก,มากไปน้อย
ขอแสดงความยินดีด้วย เพื่อนๆที่อ่านจบ ไม่ว่าจะเข้าใจหรือไม่เข้าใจก็ตาม (ด้วยภาษาที่แสนงงของผู้เขียน) มาลองทดสอบพลังด้วยโจทย์ซักหน่อยดีกว่า
เริ่มจาก Download Data Set Anime Recommendations Database จาก https://www.kaggle.com/CooperUnion/anime-recommendations-database
ส่วนใครที่ไม่ได้ตาม Anime เลย ก็คิดซะโดนเจ้าของบทความหลอกอีกครั้ง ว่ากำลังทำ Netflix Data Set นะครับ
import pandas as pd
df = pd.read_csv(‘anime.csv’)- อยากดูอนิเมะเรื่องอะไรก็ได้ ที่ผลโหวตคะแนนเยอะๆ ถ้าคะแนนเท่ากัน ดูว่าเรื่องไหนโหวตเยอะกว่าขึ้นก่อนนะ
df.sort_values([‘rating’,’members’],ascending= False)
ข้อนี้ตรงไปตรงมา เผื่อมือใหม่หลงเข้ามา
แต่สังเกตว่า เวลาเราวัดผลคะแนนอะไร เราไม่ควรจะใช้แค่ค่าเฉลี่ยเท่านั้น ความน่าเชื่อก็เป็นเรื่องสำคัญเหมือนกัน สามเรื่องบนนี่ เจ้าของโพสต์ยังไม่รู้จักเลย ในบทความต่อๆไปจะมาคุยกันเรื่องที่ว่า ต้องมีคนโหวตซักกี่คน ถึงจะเรียกว่าเชื่อถือได้
- Shingetsutan Tsukihime มีเป็นอนิเมะ ไหมครับ (ชื่อนี้เป้ะๆเลย)
df[df[‘name’] == ‘Shingetsutan Tsukihime’]
ตรงไปตรงมาเหมือนข้อข้างบนครับ เผื่อมีใครหลงมา
- D.C. Series มี VN ตั้ง 22 ภาค เป็น Anime ได้กีภาคเนี่ย แล้วภาคไหนคะแนนดีสุดอะ ได้ยินมาว่าภาค 3 นี่เฟลมากเลย จริงรึเปล่าเช็คให้หน่อยสิ
df[df[‘name’].apply(lambda x: ‘D.C.’ in x)]
ข้อนี้ไม่สามารถใช้ Operator ปกติ + Filter จะแก้ปัญหาได้แล้ว ( เพราะ ไม่มี Operator in ) ต้องใช้ .apply( ) ใน 1.3 เข้าช่วย
สังเกตข้อนี้กับข้อก่อนหน้า จะใช้ df [ Series ] ในการ Filter เหมือนกัน แตกต่างกันที่ที่มาของ Series เท่านั้น
- จะทำสร้างโมเดลอะ แต่โมเดลเรามันรับ rating มากกว่า 1 ไม่ได้อะ ทำให้เหลือ 0–1 ให้หน่อยสิ (min-max normalization มาก็พอ)
df['rating_normalization'] = (df[‘rating’] — df[‘rating’].min() )/ (df[‘rating’].max() — df[‘rating’].min())
เผื่อหลายๆคนจำไม่ได้ Operator สามารถใช้ได้กับทั้ง Numeric และ Series นะ รูปแบบนี้ตอนที่ตอนที่ต้อง implement อะไรเองจะต้องใช้ (อย่างเจ้าของโพสต์เคยใช้ custom loss fuction )
- หยิบสุดยอด Movie มาซัก 10 เรื่องสิ คนโหวตไม่น้อยกว่าสามหมื่น แต่ไม่เอาแนวทหารนะ คนโหวตต้องมากกว่า 20,000ด้วย จะได้ไม่เจอเรื่องคะแนนเยอะแต่คนโหวตหลักสิบ
df[‘genre’].apply(lambda x:not (‘Military’ in x)เวลาจะ Filter อะไร เจ้าของโพสต์ถนัดคิดก่อนว่า ต้องการ Series อะไรในการ Filter ซึ่ง Series ปกติก็สร้างได้แบบไม่มีปัญหาอะไรหรอก จนกระทั่งสร้าง Series จาก ‘genre’
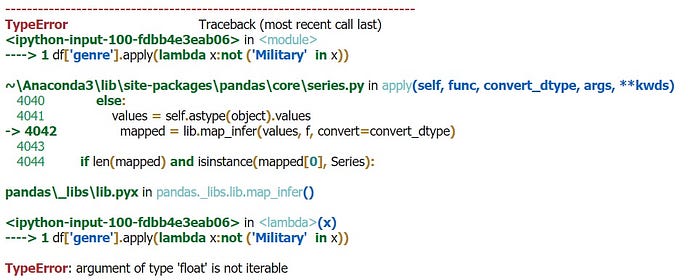
Error บอกว่า ‘Float’ ไม่สามารถ iterable ได้
แต่เอ้ะ? ‘genre’ ดูยังไงก็เป็น string นี่หว่า มี float หลุดมา? แสดงว่า Data ไม่ Clean แน่นอน ซึ่งจริงๆ Data ไม่ Clean มันก็เป็นปัญหาใหญ่ๆในวงการอยู่แล้ว
df = df[df[‘genre’].apply(lambda x:type(x)==str)]
df[‘genre’].apply(lambda x:not (‘Military’ in x))เนื่องจากบทความนี้ไม่ใช่บทความสอน Clean+EDA จริงๆ จึงขอเอา Float type ออกโดยไม่พิจารณา (แต่เจ้าของโพสต์เช็คแล้วนะ ไม่มีผลกับข้อมูลเท่าไหร่)

ขั้นตอนต่อไปก็เหมือนที่แล้วมา คือ เอา Series ไป Filter
df.loc[df[‘genre’].apply(lambda x:not (‘Military’ in x))] \
.loc[df[‘type’]==’Movie’] \
.loc[df[‘members’] > 20000] \
.sort_values(by = ‘rating’,ascending=False)[:10]
สามารถใช้ df.loc[Series] แทน df[Series] ได้ ถ้า filter ต่อกันเยอะๆจะอ่านโค๊ตได้ง่ายกว่ามากดังในตัวอย่างนี้
- One-hot Encoder gen-re ให้หน่อยสิ จะเอาไป ML Model
ปกติทั้ง pandas และ sklearn จะมี Function ในการทำ one-hot encoder อยู่แล้ว แต่ใช้ได้เฉพาะ string,numeric เท่านั้น แต่ ‘gen-re’ เป็น list ของ string จึงไม่สามารถใช้ที่ Libary มีให้ได้ (นั่นก็หมายความว่า มีโอกาศที่มากกว่า 1 Field ใน Genre one hot Encoder เป็น 1 พร้อมๆกันได้)
โจทย์นี้แบ่งออกเป็น 2 ขั้นตอน คือ การสร้าง unique Genre (List) เพื่อนำไปวนทำ One hot Encoder
อย่าลืมว่า จากข้อที่ผ่านมา ‘genre’ มี ‘float’ ติดมาด้วย ให้ Clean ออกก่อนตามขั้นด้านบน
ข้อนี้ Coding ได้หลายวิธีมาก เจ้าของโพสต์จะยกมาเพียง 1 วิธี
# list -> set -> list for get unique list
def _unique (x):
return list(set(x))u = _unique(
df[‘genre’].apply(lambda x:x.split(‘,’)) \ #string -> list
.apply(lambda x: [c.strip() for c in x]) \ #drop ' ' in each string
.sum() # concat all string to new list
)

หลังจากที่ได้ unique list มาแล้วก็ for ตรงๆเพื่อสร้าง column ของแต่ละ element ใน list
for col in u:
df[col] = df[‘genre’].apply(lambda x: 1 if col in x else 0 )
จบแล้วสำหรับ Part-1 น่าจะมีคนงงเนื้อหา แต่ทำโจทย์ได้แน่เลย แน่นอนว่าปกติเนื้อหามันก็อ่านยากกว่าทำโจทย์มาแต่ไหนแต่ไรแล้วอะนะ lol (มองอีกทางว่าอธิบายไม่ดีเอง) ถือว่าขอบคุณมากๆที่อ่านถึงบรรทัดนี้นะครับ
ต้องมีคนสงสัยแน่ๆเลย ทำไมเจ้าของโพสต์ใช้แต่กลุ่มที่ Map กลุ่ม Reduce แทบไม่ได้ใช้เลย ต้องรอติดตามต่อใน Part-2 นะครับ กับ Group By , Time Series